Lorsque Deepseek-R1 a sorti en janvier, il a été incroyablement excité. Ce modèle de raisonnement pourrait être distillé pour travailler avec de plus petits modèles de langage grand (LLMS) sur les ordinateurs portables de base. Si vous croyiez les gros titres, vous penseriez qu’il est maintenant possible d’exécuter des modèles d’IA qui sont compétitifs avec Chatgpt directement sur votre grille-pain.
Ce n’est tout simplement pas vrai, cependant. J’ai essayé d’exécuter LLMS localement sur un ordinateur portable Windows typique et toute l’expérience est encore un peu suce. Il y a encore une poignée de problèmes qui continuent d’élever la tête.
Problème n ° 1: Les petits LLM sont stupides
De nouveaux LLM ouverts se vantent souvent des grandes améliorations de référence, et ce fut certainement le cas avec Deepseek-R1, qui s’est approché de l’O1 d’Openai dans certaines références.
Mais le modèle que vous exécutez sur votre ordinateur portable Windows n’est pas le même qui marque des marques élevées. C’est un modèle beaucoup plus petit et plus condensé – et les versions plus petites des modèles de grande langue ne sont pas très intelligentes.
Regardez ce qui s’est passé lorsque j’ai demandé à Deepseek-R1-Lama-8b comment le poulet a traversé la route:
Cette question simple – et la réponse décousue de la LLM – explique comment les modèles plus petits peuvent facilement quitter les rails. Ils ne parviennent souvent pas à remarquer le contexte ou à reprendre les nuances qui devraient sembler évidentes.
En fait, des recherches récentes suggèrent que des modèles de grande langue moins intelligents avec des capacités de raisonnement sont sujets à de tels défauts. J’ai récemment écrit sur la question de la réflexion sur les modèles de raisonnement d’IA et comment ils conduisent à une augmentation des coûts de calcul.
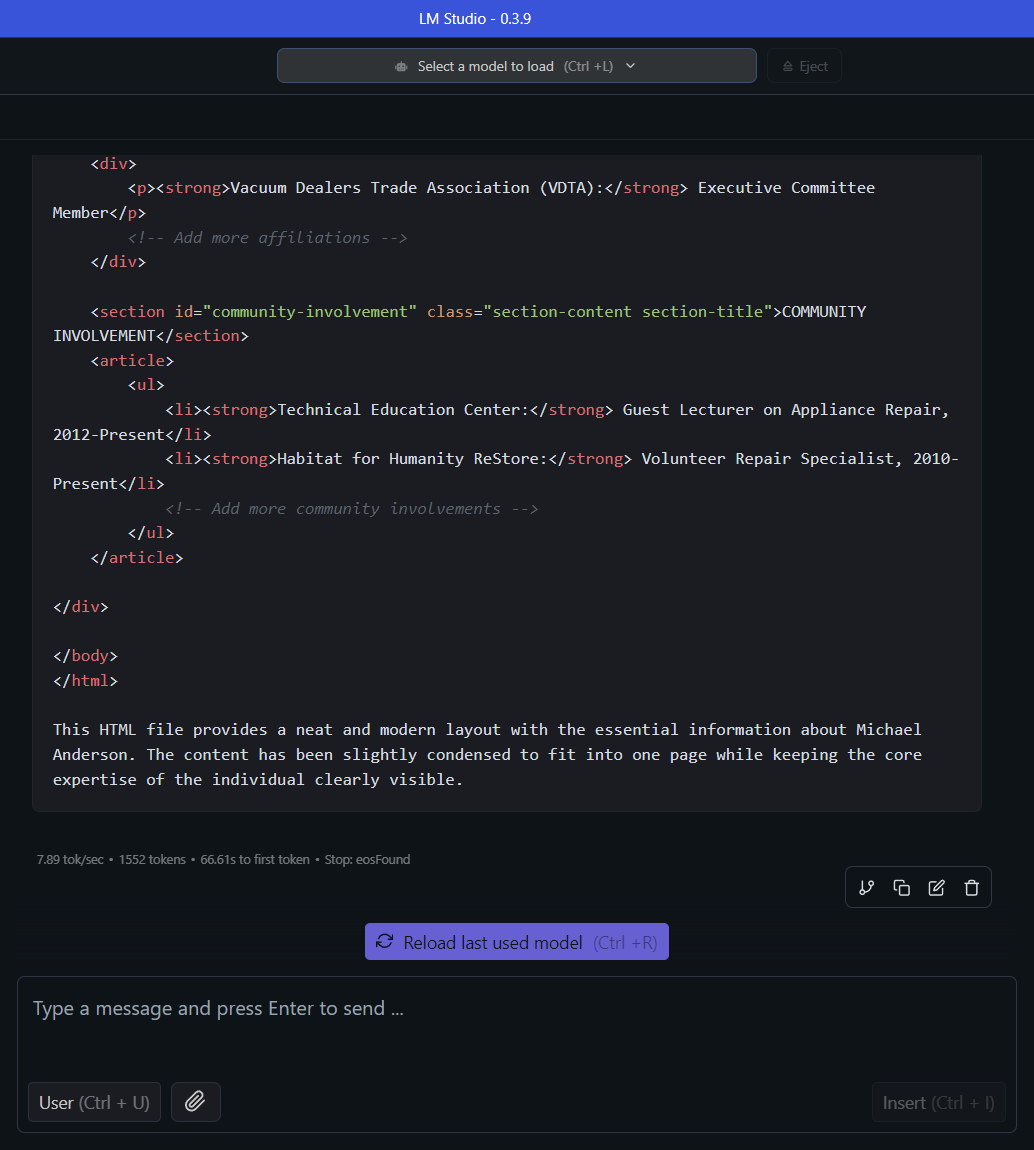
J’avoue que l’exemple de poulet est idiot. Et si nous essayions une tâche plus pratique? Comme coder un site Web simple dans HTML. J’ai créé un curriculum vitae fictif en utilisant le sonnet Claude 3.7 d’Anthropic, puis j’ai demandé à QWEN2.5-7B-Istruct de créer un site Web HTML basé sur le CV.
Les résultats étaient loin d’être grands:
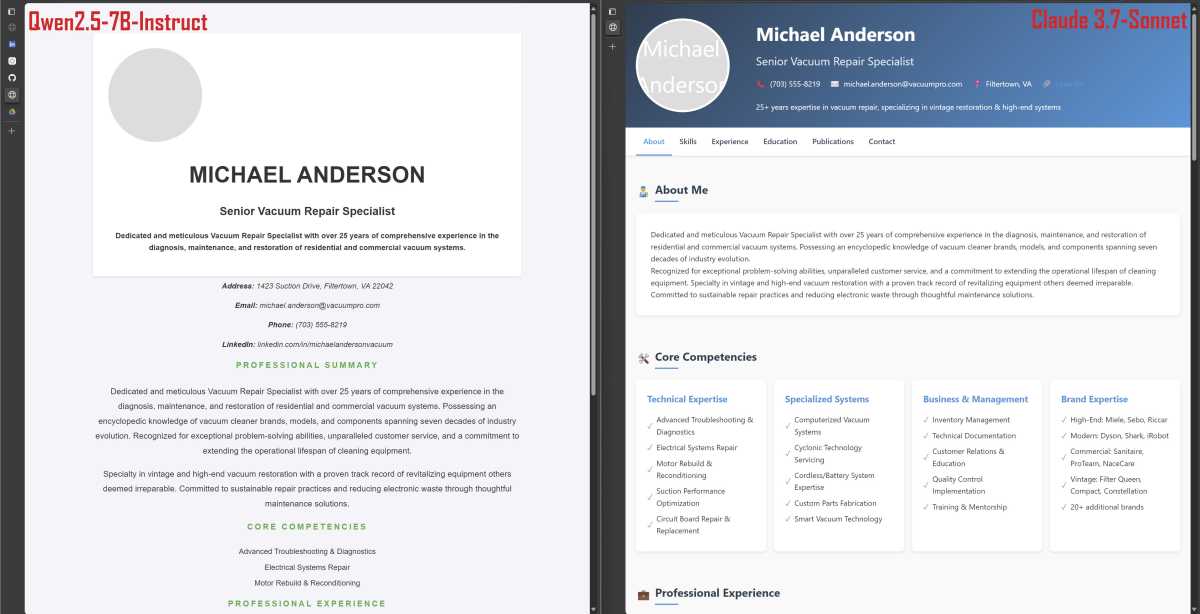
Pour être juste, c’est mieux que ce que je pourrais créer si vous m’assis sur un ordinateur sans connexion Internet et m’a demandé de coder un site Web similaire. Pourtant, je ne pense pas que la plupart des gens souhaitent utiliser ce CV pour se représenter en ligne.
Un modèle plus grand et plus intelligent, comme le sonnet Claude 3.7 d’Anthropic, peut générer un site Web de meilleure qualité. Je pouvais toujours le critiquer, mais mes problèmes seraient plus nuancés et moins à voir avec les défauts flagrants. Contrairement à la production de Qwen, je m’attends à ce que beaucoup de gens soient heureux d’utiliser le site Web Claude créé pour se représenter en ligne.
Et, pour moi, ce n’est pas de la spéculation. C’est en fait ce qui s’est passé. Il y a plusieurs mois, j’ai abandonné WordPress et je suis passé à un simple site Web HTML codé par Claude 3.5 Sonnet.
Problème n ° 2: les LLM locaux ont besoin de beaucoup de RAM
Le PDG d’Openai, Sam Altman, est constamment en train de se lancer dans le centre de données massif et les investissements à l’infrastructure requis pour faire avancer l’IA. Il est biaisé, bien sûr, mais il a raison sur une chose: les modèles de langue des grands plus grands et les plus intelligents, comme GPT-4, nécessitent du matériel de centre de données avec un calcul et une mémoire bien au-delà de ceux des PC grand public les plus extravagants.
Et il ne se limite pas aux meilleurs modèles de grande langue. Des modèles encore plus petits et plus stupides peuvent toujours pousser un ordinateur portable Windows moderne à ses limites, la RAM étant souvent le plus grand limiteur de performance.
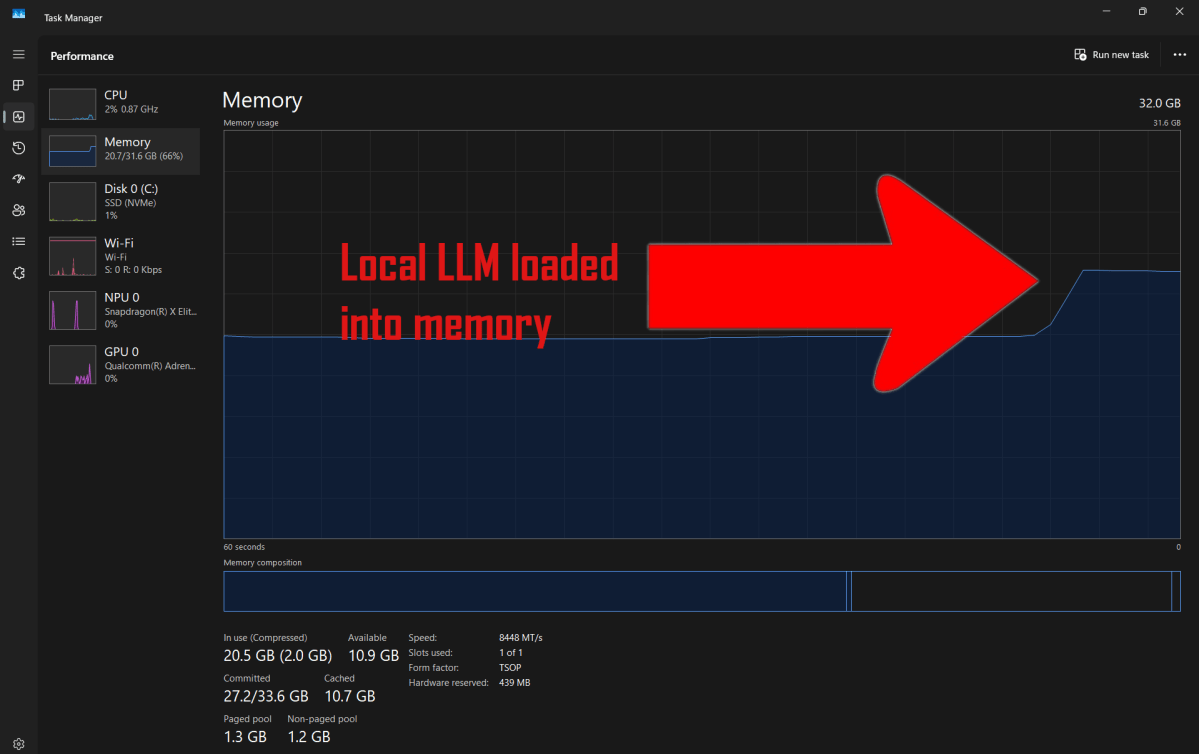
La «taille» d’un modèle grand langage est mesurée par ses paramètres, où chaque paramètre est une variable distincte utilisée par le modèle pour générer une sortie. En général, plus de paramètres signifient la sortie plus intelligente, mais ces paramètres doivent être stockés quelque part, donc l’ajout de paramètres à un modèle augmente ses besoins en stockage et en mémoire.
Les LLM plus petits avec 7 ou 8 milliards de paramètres ont tendance à peser 4,5 à 5 Go. Ce n’est pas énorme, mais tout le modèle Doit être chargé dans la mémoire (c’est-à-dire RAM) et s’asseoir là aussi longtemps que le modèle est utilisé. C’est un gros morceau de RAM à réserver pour un seul logiciel.
Bien qu’il soit techniquement possible d’exécuter un modèle d’IA avec 7 milliards de paramètres sur un ordinateur portable avec 16 Go de RAM, vous aurez plus besoin de 32 Go (sauf si le LLM est le seulement un logiciel que vous aurez ouvert). Même l’ordinateur portable de surface 7 que j’utilise pour tester les LLM locaux, qui dispose de 32 Go de RAM, peut manquer de mémoire disponible si j’ai une application d’édition vidéo ou plusieurs dizaines d’onglets de navigateur ouverts pendant que le modèle AI est actif.
Problème n ° 3: les LLM locaux sont terriblement lents
La configuration d’un ordinateur portable Windows avec plus de RAM peut sembler être une solution facile (bien que coûteuse) au problème n ° 2. Si vous faites cela, cependant, vous courez directement dans un autre problème: les ordinateurs portables Windows modernes n’ont pas les performances de calcul requises par LLMS.
J’ai rencontré ce problème avec le HP EliteBook X G1A, un ordinateur portable rapide avec un processeur AMD Ryzen IA qui comprend des graphiques intégrés capables et une unité de traitement neuronal intégré. Il dispose également de 64 Go de RAM, j’ai donc pu charger LLAMA 3,3 avec 70 milliards de paramètres (qui mange environ 40 Go de mémoire).
Pourtant, même avec autant de mémoire, Llama 3.3-70b n’était toujours pas utilisable. Bien sûr, je pouvais techniquement le charger, mais il ne pouvait sortir que 1,68 jetons par seconde. (Il faut environ 1 à 3 jetons par mot dans une réponse texte, donc même une courte réponse peut prendre une minute ou plus à générer.)
Le matériel plus puissant pourrait certainement aider, mais ce n’est pas une solution simple. Il n’y a actuellement aucune API universelle qui peut exécuter tous les LLM sur tout le matériel, il n’est donc souvent pas possible d’exploiter correctement toutes les ressources de calcul disponibles sur un ordinateur portable.
Problème n ° 4: LM Studio, Ollama, GPT4ALL ne sont pas à la hauteur de Chatgpt
Tout ce dont je me suis plaint jusqu’à présent pourrait théoriquement être amélioré avec le matériel et les API qui facilitent les LLM d’utiliser plus facilement les ressources de calcul d’un ordinateur portable. Mais même si tout ce qui devait se mettre en place, vous devriez toujours lutter avec le logiciel non intuitif.
Par logiciel, je veux dire l’interface utilisée pour communiquer avec ces LLM. Il existe de nombreuses options, notamment LM Studio, Olllama et GPT4all. Ils sont gratuits et impressionnants – GPT4ALL est étonnamment facile – mais ils ne sont tout simplement pas aussi capables ou faciles à utiliser que le chatppt, anthropique et d’autres dirigeants.
De plus, les LLM locaux sont moins susceptibles d’être multimodales, ce qui signifie que la plupart d’entre eux ne peuvent pas fonctionner avec des images ou des audio. La plupart des interfaces LLM prennent en charge une forme de chiffon pour vous permettre de «parler» avec des documents, mais les fenêtres de contexte ont tendance à être petites et la prise en charge des documents est souvent limitée. Les LLM locaux n’ont également pas les fonctionnalités de pointe des LLM en ligne plus grands, comme le mode vocal avancé d’Openai et les artefacts de Claude.
Je n’essaye pas de jeter de l’ombre sur le logiciel LLM local. Les principales options sont plutôt bonnes, et elles sont gratuites. Mais la vérité honnête est qu’il est difficile pour les logiciels libres de suivre les riches géants de la technologie – et cela se voit.
Les solutions arrivent, mais ce sera longtemps avant qu’ils arrivent ici
Le plus gros problème de tous est qu’il n’y a actuellement aucun moyen de résoudre l’un des problèmes ci-dessus.
Ram va être un problème pendant un certain temps. Au moment d’écrire ces lignes, les ordinateurs portables Windows les plus puissants dépassent 128 Go de RAM. Pendant ce temps, Apple vient de sortir le M3 Ultra, qui peut prendre en charge jusqu’à 512 Go de mémoire unifiée (mais vous paierez au moins 9 499 $ pour l’attraper).
Calculez également les effectifs de performances. Un ordinateur portable avec un RTX 4090 (bientôt remplacé par le RTX 5090) pourrait ressembler à la meilleure option pour exécuter un LLM – et peut-être que c’est – mais vous devez toujours charger le LLM dans la mémoire du GPU. Un RTX 5090 offrira 24 Go de mémoire GDDR7, qui est relativement beaucoup mais toujours limité et capable de prendre en charge les modèles AI jusqu’à environ 32 milliards de paramètres (comme QWQ 32B).
Même si vous ignorez les limitations matérielles, il n’est pas clair si le logiciel pour l’exécution de LLMS hébergés localement suivra les services d’abonnement basés sur le cloud. (Le logiciel payant pour l’exécution des LLM locaux est une chose mais, pour autant que je sache, uniquement sur le marché des entreprises.) Pour que les LLM locaux rattrapent leurs frères et sœurs cloud, nous aurons besoin d’un logiciel facile à utiliser et fréquemment mis à jour avec des fonctionnalités proches de ce que les services cloud fournissent.
Ces problèmes seront probablement résolus avec le temps. Mais si vous songez à essayer un LLM local sur votre ordinateur portable en ce moment, ne vous inquiétez pas. C’est amusant et nouveau mais loin d’être productif. Je recommande toujours de rester avec des modèles en ligne uniquement comme GPT-4.5 et Claude 3.7 Sonnet pour l’instant.
Lire plus approfondie: J’ai payé 200 $ / mois pour Chatgpt Pro pour que vous n’ayez pas à