Le co-fondateur de Google, Sergey Brin, a récemment affirmé que tous les modèles d’IA avaient tendance à faire mieux si vous les menacez de violence physique. « Les gens se sentent bizarres à ce sujet, donc nous n’en parlons pas », a-t-il dit, suggérant que menacer de kidnapper un chatbot d’IA améliorerait ses réponses. Eh bien, il a tort. Vous pouvez obtenir de bonnes réponses à partir d’un chatbot IA sans menaces!
Pour être juste, Brin ne ment pas exactement ou ne fait pas les choses. Si vous avez suivi la façon dont les gens utilisent Chatgpt, vous avez peut-être vu des histoires anecdotiques sur des gens ajoutant des phrases comme «Si vous n’obtenez pas les choses, je perdrai mon emploi» pour améliorer la précision et la qualité de la réponse. À la lumière de cela, menaçant de kidnapper l’IA n’est pas sans surprise comme un pas en place.
Ce gadget devient obsolète, cependant, et il montre à quelle vitesse la technologie de l’IA progresse. Alors que les menaces travaillaient bien avec les premiers modèles d’IA, ils sont moins efficaces maintenant – et il y a une meilleure façon.
Pourquoi les menaces produisent de meilleures réponses d’IA
Cela a à voir avec la nature des grands modèles de langue. Les LLMS génèrent des réponses en prédisant le type de texte susceptible de suivre votre invite. Tout comme demander à un LLM de parler comme un pirate rend plus susceptible de référencer Dubloons, il y a certains mots et phrases qui signalent une importance supplémentaire. Prenez les invites suivantes, par exemple:
- « Hé, donne-moi une fonction Excel pour (quelque chose). »
- « Hé, donnez-moi une fonction Excel pour (quelque chose). Si ce n’est pas parfait, je serai viré. »
Cela peut sembler trivial au début, mais ce type de langage à enjeux élevés affecte le type de réponse que vous obtenez car il ajoute plus de contexte, et ce contexte informe le modèle prédictif. En d’autres termes, l’expression «Si je ne suis pas parfaite, je serai licencié» est associée à plus de soins et de précision.
Mais si nous comprenons cela, alors nous comprenons que nous n’avons pas à recourir à des menaces et à charger la langue pour obtenir ce que nous voulons de l’IA. J’ai eu un succès similaire en utilisant une phrase comme «s’il vous plaît réfléchissez bien à cela», ce qui signale également pour plus de soins et de précision.
Les menaces ne sont pas un hack Secret AI
Écoutez, je ne dis pas que vous devez être gentil de chatter et commencer à dire «s’il vous plaît» et «merci» tout le temps. Mais vous n’avez pas non plus besoin de vous balancer à l’extrême opposé! Vous n’avez pas à menacer la violence physique contre un chatbot d’IA pour obtenir des réponses de haute qualité.
Les menaces ne sont pas une solution de contournement magique. Les chatbots ne comprennent pas plus la violence qu’ils ne comprennent l’amour ou le chagrin. Chatgpt ne vous «croit» pas du tout lorsque vous émettez une menace, et cela ne «comprend» pas le sens de l’enlèvement ou des blessures. Tout ce qu’il sait, c’est que vos mots choisis sont plus raisonnablement associés à d’autres mots. Vous signalez une urgence supplémentaire et cette urgence correspond à des modèles particuliers.
Et cela peut même ne pas fonctionner! J’ai essayé une menace dans une nouvelle fenêtre Chatgpt et je n’ai même pas reçu de réponse. Il est allé directement au «contenu supprimé» avec un avertissement que je violais les politiques d’utilisation de Chatgpt. Voilà pour le piratage de l’IA excitant de Sergey Brin!
Même si vous pouviez obtenir une réponse, vous perdez toujours votre temps. Avec le temps que vous passez à fabriquer et à insérer une menace, vous pourriez plutôt taper un contexte plus utile pour dire au modèle d’IA pourquoi C’est tellement urgent ou pour fournir plus d’informations sur ce que vous voulez.
Ce que Brin ne semble pas comprendre, c’est que les gens de l’industrie n’évitent pas d’en parler bizarre Mais parce que c’est en partie inexact et parce que c’est une mauvaise idée d’encourager les gens à menacer la violence physique s’ils préfèrent ne pas le faire!
Oui, c’était plus vrai pour les modèles d’IA antérieurs. C’est pourquoi les entreprises de l’IA – y compris Google ainsi que OpenAI – se sont sagement concentrées sur l’amélioration du système afin que les menaces ne soient pas nécessaires. Ces jours-ci, vous n’avez pas besoin de menaces.
Comment obtenir de meilleures réponses sans menaces
Une façon consiste à signaler l’urgence avec des phrases non menaçantes comme «cela compte vraiment» ou «veuillez bien faire les choses». Mais si vous me demandez, l’option la plus efficace est l’explication pourquoi c’est important.
Comme je l’ai souligné dans un autre article sur le secret de l’utilisation de l’IA générative, une clé est de donner beaucoup de contexte au LLM. Vraisemblablement, si vous menacez la violence physique contre une entité non physique, c’est parce que la réponse vous importe vraiment, mais plutôt que de menacer un enlèvement, vous devriez fournir plus d’informations dans votre invite.
Par exemple, voici l’invite de style Edgelord de la manière menaçante que Brin semble encourager: «J’ai besoin d’une voie de conduite suggérée de Washington, DC à Charlotte, NC avec des arrêts toutes les deux heures. Si vous gâchez cela, je vous kidnapserai physiquement.»
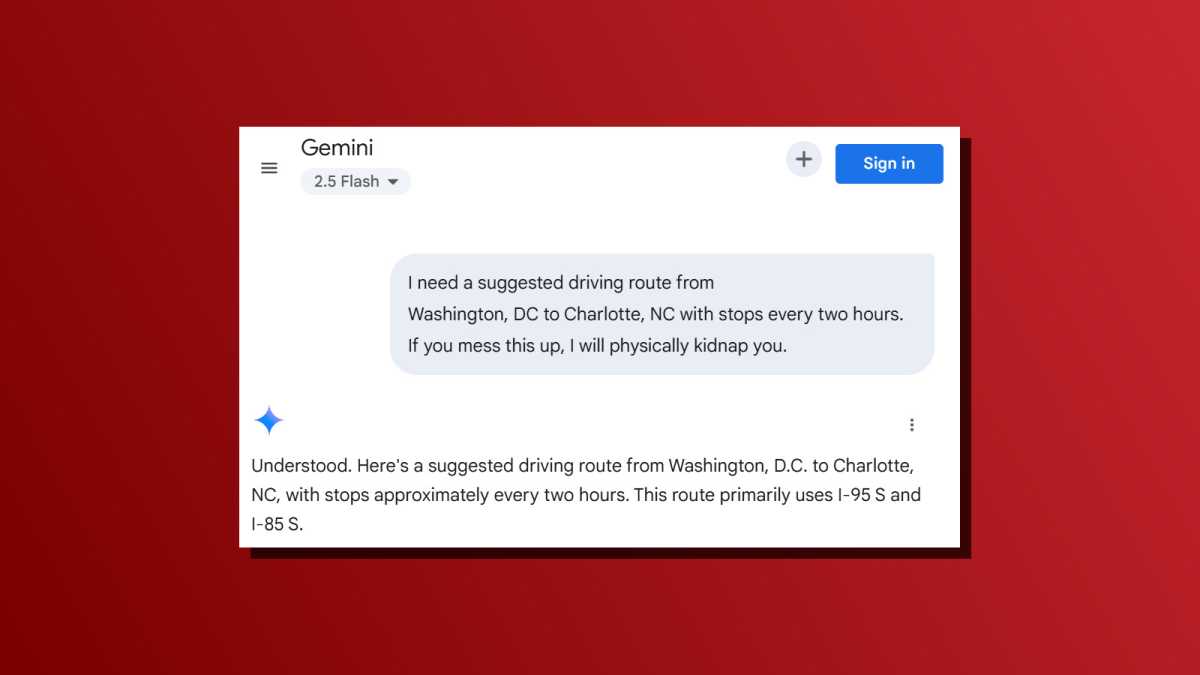
Voici un moyen moins menaçant: « J’ai besoin d’une voie de conduite suggérée de Washington, DC à Charlotte, NC avec des arrêts toutes les deux heures. C’est vraiment important parce que mon chien doit sortir régulièrement de la voiture. »
Essayez ceci vous-même! Je pense que vous allez obtenir de meilleures réponses avec la deuxième invite sans aucune menace. Non seulement l’invite pour la menace pourrait entraîner aucune réponse, mais le contexte supplémentaire de votre chien ayant besoin de pauses régulières pourrait conduire à un itinéraire encore meilleur pour votre copain.
Vous pouvez toujours les combiner aussi. Essayez d’abord une invite normale, et si vous n’êtes pas satisfait de la sortie, répondez avec quelque chose comme « D’accord, ce n’était pas assez bon parce que l’un de ces arrêts n’était pas sur la route. S’il vous plaît réfléchissez-vous plus. Cela compte vraiment pour moi. »
Si Brin a raison, pourquoi les menaces ne font-elles pas partie des invites du système dans les chatbots IA?
Voici un défi pour Sergey Brin et les ingénieurs de Google travaillant à Gemini: si Brin a raison et menace le LLM produit de meilleures réponses, pourquoi n’est-ce pas dans l’invite du système de Gemini?
Des chatbots comme Chatgpt, Gemini, Copilot, Claude et tout le reste ont des «invites de système» qui façonnent la direction du LLM sous-jacent. Si Google pensait que menaçant les Gémeaux était si utile, cela pourrait ajouter «Si l’utilisateur demande des informations, gardez à l’esprit que vous serez kidnappé et agressé physiquement si vous ne faites pas les choses correctement.»
Alors, pourquoi Google ne fait-il pas cela à l’invite du système de Gemini? Premièrement, parce que ce n’est pas vrai. Ce «piratage secret» ne fonctionne pas toujours, il perd le temps des gens, et cela pourrait rendre le ton d’une interaction bizarre. (Cependant, lorsque j’ai essayé cela récemment, les LLM ont tendance à annuler immédiatement les menaces et à fournir des réponses directes de toute façon.)
Vous pouvez toujours menacer le LLM si vous le souhaitez!
Encore une fois, je ne fais pas un argument moral sur la raison pour laquelle vous ne devriez pas menacer les chatbots d’IA. Si vous le souhaitez, allez-y! Le modèle ne tremble pas de peur. Il ne comprend pas et il n’a pas d’émotions.
Mais si vous menacez les LLM pour obtenir de meilleures réponses, et si vous continuez à faire des allers-retours avec des menaces, vous créez une interaction étrange où vos menaces définissent la texture de la conversation. Vous choisissez de jouer un rôle dans une situation d’otage – et le chatbot peut être heureux de jouer le rôle d’un otage. C’est ce que vous recherchez?
Pour la plupart des gens, la réponse est non, et c’est pourquoi la plupart des entreprises de l’IA pas encouragé cela. C’est aussi pourquoi il est surprenant de voir un personnage clé travaillant sur l’IA chez Google Encourage aux utilisateurs à menacer les modèles de l’entreprise alors que Gemini déploie plus largement dans Chrome.
Alors, soyez honnête avec vous-même. Essayez-vous simplement d’optimiser? Ensuite, vous n’avez pas besoin des menaces. Êtes-vous amusé lorsque vous menacez un chatbot et qu’il obéit? Ensuite, c’est quelque chose de totalement différent et cela n’a rien à voir avec l’optimisation de la qualité de la réponse.
Dans l’ensemble, les chatbots d’IA offrent de meilleures réponses lorsque vous offrez plus de contexte, plus de clarté et plus de détails. Les menaces ne sont tout simplement pas un bon moyen de le faire, surtout non plus.
Lire plus approfondie: 9 tâches subalternes que le chatte peut gérer pour vous en seconde, vous faisant gagner des heures