Si vous ne le savez pas, Nvidia investit 5 milliards de dollars dans Intel. Selon Jensen Huang, PDG de Nvidia, cette alliance passionnante Nvidia-Intel créera « des SoC Intel x86 intégrant les chipsets GPU Nvidia, fusionnant les meilleurs CPU et GPU au monde ». Cela pourrait être l’injection dont Intel a besoin pour sortir de son funk et corriger sa trajectoire descendante.
Mais cette fusion ne consiste pas seulement, par exemple, à améliorer les graphiques intégrés Arc d’Intel. C’est en fait un pas vers la domination de l’IA sur PC. Les GPU Nvidia constituent depuis longtemps le meilleur matériel pour les charges de travail d’IA locales, mais ils sont limités par la VRAM. Avec l’aide d’Intel, Nvidia pourrait enfin résoudre ce goulot d’étranglement en développant la même puissance qu’Apple.
je parle de mémoire unifiée
Imaginez un ordinateur de bureau moderne équipé d’un processeur Intel et d’un GPU Nvidia. Le processeur Intel s’appuie sur la RAM de la carte mère tandis que le GPU Nvidia s’appuie sur la VRAM intégrée. Pour communiquer, ils doivent déplacer les données entre la RAM et la VRAM, et c’est lent.
Pour les jeux sur PC, ce n’est pas un problème majeur. Par exemple, une Nvidia GeForce RTX 5080 dispose de 16 Go de VRAM, ce qui est suffisant pour les jeux. Mais pour les tâches de calcul GPU, la VRAM est essentiellement l’espace de travail des données, donc plus de VRAM est préférable. Ceci est essentiel pour les LLM locaux et autres tâches d’IA locales, mais également pour toutes les charges de travail CUDA sur les GPU Nvidia.
En d’autres termes : si vous souhaitez exécuter un LLM local sur votre bureau, il doit tenir dans la mémoire de votre GPU. Vous avez un ordinateur de bureau avec 128 Go de RAM ? Cela n’a pas d’importance. Si votre GPU ne dispose que de 16 Go de VRAM, c’est votre limite, et ce n’est tout simplement pas suffisant pour l’IA de nouvelle génération.
Oui, Nvidia possède le système de calcul GPU le plus mature et les GPU les plus rapides et les plus puissants au monde. Mais pour en profiter pour des tâches gourmandes en mémoire, il faut beaucoup de VRAM. À un moment donné, ce n’est plus une question de GPU vitesse– il s’agit du nombre de gigaoctets de données que vous pouvez insérer dans le GPU mémoire pour un accès direct et rapide.
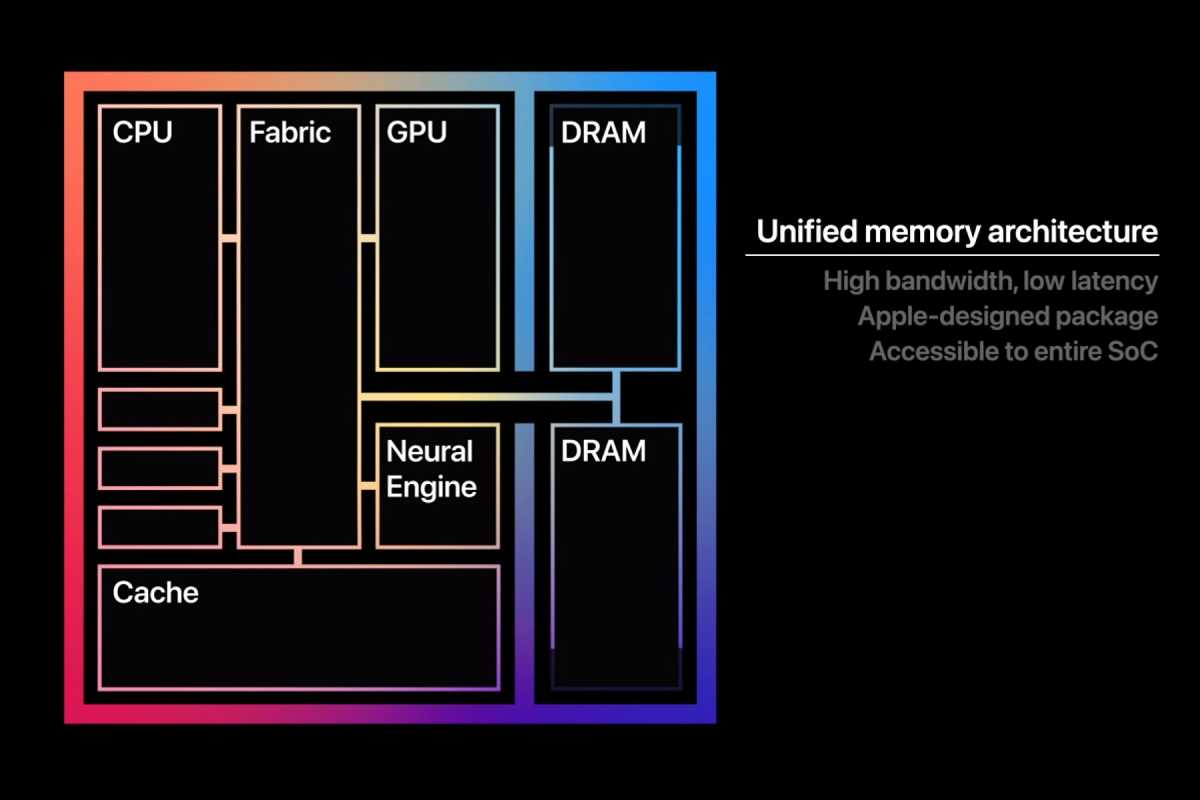
Entrez dans la mémoire unifiée. Vous pouvez considérer la mémoire unifiée comme un pool unique de RAM partagé entre le CPU et le GPU. Avec la mémoire unifiée, la communication entre le CPU et le GPU est plus rapide puisque les données n’ont pas besoin d’être constamment déplacées de la RAM vers la VRAM et vice versa. Cela augmente également la quantité de RAM à laquelle le GPU a accès.
Maintenant, permettez-moi d’être clair : Intel et Nvidia n’ont PAS annoncé de mémoire unifiée. Pas encore, en tout cas. Mais ils ont annoncé quelque chose de proche : l’intégration d’un chipset GPU Nvidia sur le même package SoC qu’un CPU Intel, connecté avec NVLink. Et dans ses produits pour centres de données, NVLink-C2C permet au CPU et au GPU de partager la mémoire. Cela vous semble familier ?
AMD, Apple et Qualcomm ont déjà tous une mémoire partagée
Du côté des Mac, Apple Silicon est l’exemple même de la mémoire unifiée. Vous pouvez acheter un MacBook avec 128 Go de mémoire unifiée, et cette mémoire peut être utilisée à la fois par le processeur et le GPU du MacBook.
Pendant ce temps, une Nvidia GeForce RTX 5090 dispose de 32 Go de VRAM. Pour les charges de travail d’IA où la capacité de mémoire constitue le goulot d’étranglement, un MacBook peut surpasser un PC de bureau costaud doté d’un processeur Intel haut de gamme et d’un RTX 5090, même si le GPU RTX de Nvidia est beaucoup plus rapide que celui d’Apple.
Vous disposez également de l’architecture APU d’AMD (qui offre une mémoire système partagée entre le CPU et le GPU), du Snapdragon X de Qualcomm (qui possède une mémoire unifiée comme Apple) et de la plate-forme Lunar Lake d’Intel (qui dispose d’une mémoire intégrée partagée entre le CPU et le GPU).
Le Ryzen AI Max+ d’AMD prend en charge jusqu’à 128 Go de mémoire maximum, mais de nombreux outils d’IA et charges de travail de calcul GPU sont conçus pour CUDA, la plate-forme logicielle de Nvidia. Sans CUDA, ce système AMD risque de ne pas être compatible avec les outils que vous souhaitez exécuter. (Et ces GPU Qualcomm et Intel intégrés ne sont tout simplement pas si rapides. À l’heure actuelle, seuls AMD et Apple sont véritablement en lice.)
Bien qu’ils disposent d’une mémoire unifiée, Apple, AMD, Qualcomm et Intel ne disposent pas des puissants GPU de Nvidia ni de la plate-forme CUDA mature qui fait de Nvidia la norme pour les tâches de calcul GPU. Pourtant, même si CUDA est le standard de facto, l’industrie tente de changer cela avec des technologies comme Windows ML. Les concurrents réduisent ici l’avance de Nvidia.
Pour reprendre de l’avance, Nvidia doit trouver un moyen pour ses GPU d’accéder au pool de mémoire principal d’un système, tout comme Apple, AMD et Qualcomm le permettent déjà sur leurs SoC. Peu importe si Nvidia dispose de la solution de calcul GPU la plus puissante si les modèles et les données d’IA ne peuvent pas s’intégrer dans la VRAM de ladite solution.
Ce n’est pas officiel, mais les indices sont là
Dans l’annonce officielle de Nvidia, la société déclare « Intel construira et proposera au marché des systèmes sur puces (SOC) x86 intégrant les chipsets GPU Nvidia RTX. Ces nouveaux SOC RTX x86 alimenteront une large gamme de PC qui nécessitent l’intégration de processeurs et de GPU de classe mondiale. » Et dans l’annonce officielle d’Intel, les deux « se concentreront sur la connexion transparente des architectures Nvidia et Intel à l’aide de Nvidia NVLink ».
Donc oui, il n’y a pas beaucoup de détails ici, et ni Nvidia ni Intel ne parlent de mémoire. La mémoire sera-t-elle sur le GPU lui-même ? Eh bien, Nvidia décrit cela comme « une nouvelle classe de graphiques intégrés ». À l’heure actuelle, tous les principaux SoC dotés de graphiques intégrés (d’Apple, AMD, Qualcomm et même Intel lui-même) utilisent une mémoire unifiée ou mutualisée. (Certaines plates-formes ont une mémoire unifiée au niveau matériel, tandis que d’autres permettent simplement au GPU de partager rapidement l’accès à la RAM du système. La clé est que le GPU n’est pas seulement coincé avec sa propre petite quantité de VRAM.)

Nvidia et Intel n’ont pas annoncé quand ils livreront du matériel avec cette architecture, mais plusieurs analystes prévoient 2027. Il ne s’agit cependant pas d’un partenariat ponctuel et il se poursuivra. Le premier package SoC ne sera pas le dernier et l’architecture évoluera probablement… et je pense qu’elle évoluera vers une intégration plus étroite entre les processeurs Intel et les GPU Nvidia.
Ainsi, même si Nvidia et Intel n’ont pas officiellement annoncé de mémoire unifiée (en fait, ils n’ont rien dit sur la mémoire), cela semble être une direction judicieuse. Tous les discours sur un « SoC géant virtuel » où le CPU et le GPU sont « connectés de manière transparente » sont un indice fort sur la direction que cela prend, et NVLink est un autre indice important. Dans ses produits pour centres de données, Nvidia propose une forme de NVLink (appelée NVLink-C2C) qui permet aux CPU et aux GPU d’utiliser le même pool de mémoire. (Il n’y a aucune garantie que ce sera le cas, bien sûr, surtout dans la première génération.)
Permettez-moi de porter mon chapeau de spéculation éclairée pendant une seconde : Nvidia et Intel adoreraient tous deux proposer une architecture de mémoire unifiée, mais il faudra plusieurs générations de matériel pour y parvenir, et je parierais que les ingénieurs de Nvidia et d’Intel en parlent déjà au moment où nous parlons. Le produit de première génération ne sera probablement pas une véritable mémoire unifiée – Intel et Nvidia en parleraient dans leurs communiqués de presse si c’était le cas – mais ils vont presque certainement dans cette direction.
Nous devrons attendre pour plus de détails, mais Nvidia a enfin une voie plausible pour écraser ses concurrents dans la guerre des PC IA. Nvidia possède déjà le meilleur système GPU ; la seule pièce manquante est la mémoire. Avec Intel à bord, Nvidia dispose désormais d’une feuille de route pour arriver là où elle doit être. Mais Nvidia et Intel auront besoin de temps pour proposer le bon produit, et j’imagine que c’est pour cela qu’ils ne parlent pas encore de mémoire. Restez à l’écoute.
Abonnez-vous à la newsletter de Chris Hoffman, Le fichier Lisez-moi de Windowspour des conseils informatiques plus experts d’un véritable humain.